
A comparison study to detect seam carving forgery in JPEG images with deep learning models

Abstract
Aim: Although deep learning has been applied in image forgery detection, to our knowledge, it still falls short of a comprehensive comparison study in detecting seam-carving images in multimedia forensics by comparing the popular deep learning models, which is addressed in this study.
Methods: To investigate the performance in detecting seam-carving-based image forgery with popular deep learning models that were used in image forensics, we compared nine different deep learning models in detecting untouched JPEG images, seam-insertion images, and seam removal images (three-class classification), and in distinguishing modified seam-carving images from untouched JPEG images (binary classification). We also investigate the different learning algorithms with the Efficientnet-B5 in adjusting the learning rate with three popular optimizers in deep learning.
Results: Our study shows that EfficientNet performs the best among the nine different deep learning frameworks, followed by SRnet, and LFnet. Different algorithms for adjusting the learning rate result in different detection testing accuracy with Efficientnet-B5. In our experiments, decouples the optimal choice of weight decay factor from the setting of the learning rate (AdamW) is generally superior to Adaptive Moment Estimation (Adam) and Stochastic Gradient Descent (SGD). Our study also indicates that deep learning is very promising for image forensics, such as the detection of image forgery.
Conclusion: Deep learning is very promising in image forensics that is hardly discernable to human perceptions, but the performance varies over different learning models and frameworks. In addition to the models, the optimizer has a considerable impact on the final detection performance. We would recommend EfficientNet, LFnet and SRnet for seam-carving detection.
Keywords
INTRODUCTION
Digital images have played an essential role in our daily lives. Digital image editing tools are easily available and have evolved tremendously due to the increasing requests. With the popularity of open-source image editing tools that are easily accessible, many individuals without advanced image processing techniques can effortlessly generate a fake image. Hence, the authenticity of the images in the virtual environment becomes a critical problem[1, 2].
Seam carving is one of the popular image manipulation strategies adequate for content-aware image resizing. The functionality of seam carving is to assemble several seams in an image and automatically eliminate seams to decrease image size or insert seams to extend it. The corresponding image is reduced by one pixel in height/width at a time. In seam carving, the idea is that the given input image is resized by removing or inserting optimal seams described as corresponding pixel paths reaching from top to bottom or left to right while keeping the photorealism of the image. The seam located vertically in an image is a path of pixels linked with one pixel per row from top to bottom. The seam located horizontally is a way of pixels linked from left to right with one pixel per column. Hence, the underlying algorithm is elegant and straightforward. By reducing the energy cost of a seam[3, 4] to re-generate an image, seam carving can efficiently resize an image[5]. By using seam carving, an unwanted object can be removed from an image without any perceivable distortion[6, 7].
As mentioned, seam carving has been applied for object removal and image resizing; it is also applied for tampering with illusions such as image or object insertion in image. Seam carved images can be intentionally manipulated to misinterpret or extract original content in the image; thus, detecting the forgery content, which are artifacts of seam carving, has evolved into a crucial issue in multimedia forensics[8, 9].
In image forensics, many methods have been proposed to detect image steganography and image forgery, including but not limited to the detection of seam carving. These methods may potentially be applied to the detection of seam carving forgery. These works contain the detection of distinct image manipulations such as morphing[10, 11], resampling[12, 13], splicing[14, 15], copy-move[16, 17], seam carving[18, 19], and inpainting based-object removal[20, 21]. Some approaches also exploit JPEG blocking artifacts to detect tampered regions[22, 23], while more recent research exploits deep learning-based methods[24-26].
RELATED WORK
Introduction to seam carving
In seam carving, imperceptible pixels on the least essential seams coordinating with their surroundings are terminated or inserted to perform content-aware scaling. Formally, let I will be a
where x is a mapping x: [1, ..., p]⊠[1, ..., q].
Similarly, a horizontal seam is defined by:
where y is a mapping y: [1, ..., q]⊠[1, ..., p].
The pixel path of seam S is denoted as
In the reference[4], several image importance measures are examined as the energy function. Although no single energy function performs well across all images, in general, the following two measures e1 and eHoG work quite well.
where
Seam carving and relevant image forgery detection
Sarker et al.[5] proposed a blind seam carving detection system which models the distinction JPEG 2-D array with Markov random process[27]; in their detection system, the Markov features are utilized to exhibit the imprint in block-based frequency-domain to distinguish modified images from original ones. Fillion and Sharma[28] proposed a model comprising energy bias-based features and decisive wavelet moments to detect seam carving. Chang et al.[29] illustrated the artifact caused by seam carving in JPEG images. They discussed the misalignment due to the modification occurrence, and seam-carved images and unaltered images may have distinctive DCT blocking artifacts when recompression has been made[30]. Liu et al.[7] proposed rich model-based features[31] with calibrated neighboring joint density and a hybrid large feature mining approach to achieve state-of-the-art in terms of detection accuracy[32]. Deep learning is widely used for various areas[33-39], it is also applied to detect image forgery[40-42]. For example, Yao et al.[43] developed a reliability fusion map based CNN model to detect image forgery. Du et al.[44] proposed a locality-aware autoencoder to detect deepfake images. The authors used a pixel-wise mask to regularize the local interpretation of Locality-Aware AutoEncoders to improve the model's generalization capabilities. The authors evaluated their proposed approach on the Dresden dataset. They claimed that their model achieved high performance. Thakur et al.[45] proposed two algorithms to classify and localize image forgery. The authors evaluated their proposed approach using the CASIA-v1, CASIA-v2, DVMM, and BSDS300 datasets. They reported that their proposed approach achieved state-of-the-art performance. Majumder et al.[42] developed a CNN architecture to train a model for forgery detection. The researchers tested their solution on the CASIA v2 dataset. They also applied transfer learning to adapt VGG-16, VGG-19, and Resnet models for forgery detection. The authors compared the performance of their proposed model with the transfer learning models. Their method achieved good performance without multi-level feature extraction, and that transfer learning is unsuitable for this task. Muhammad et al.[46] developed an image forgery detection method based on the steerable pyramid transform and local binary pattern techniques. Their proposed method was evaluated on three datasets: CASIA v1, CASIA v2, and Columbia color image. Goel et al.[47] developed a copy move forgery detection algorithm that uses dual branch convolutional neural networks to identify forged images. Le-Tien et al.[48] developed a technique to identify forged images using neural networks. The authors evaluated their model on the CASIA-v2 dataset. Diallo et al.[41] developed a framework for deep learning detection of forged images. The researchers evaluated their proposed framework on the CMI dataset. They also evaluated a set of transfer learning models adapted to forgery detection, namely, ResNet, VGG-19, and DenseNet. Han et al.[49] applied Maximum Mean Discrepancy (MMD) loss to train a machine learning model for forgery detection. The authors evaluated their proposed approach on the DF-TIMIT, UADFV, Celeb-DF, and FaceForensics++ datasets. Aneja et al.[50] developed a new transfer learning approach for forgery detection. The authors evaluated their approach on the FaceForensics++ dataset. Bourouis et al.[51] developed a framework for the Bayesian learning of finite GID mixture models. The authors evaluated their approach using forgery detection. The datasets used are MICC-F220 and MICC-F2000. Cao et al.[52] developed an anti-compression facial forgery detection technique which extracts compression insensitive features from compressed and uncompressed forgeries and learns a robust partition. Asghar et al.[53] developed an image forensics technique that uses discriminative robust local binary patterns to encode tamper traces. Their approach also uses an SVM classifier to detect forged images. Zhang et al.[54] applied a cross-layer intersection mechanism to a dense u-net classifier for image forgery detection. They evaluated their approach on several datasets: CASIA, NC2016, and Columbia Uncompressed. Optimization needs to be performed during detections[55-58]. Other seam-carving-based detection includes but not limited to[59-62].
Deep learning model-based approaches are widely applied for image forgery detection. These techniques can improve different aspects of life and research on image forgery detection is required. Unfortunately, it falls short of a comprehensive comparison of the state-of-the-art deep learning models in detection image forgery, especially seam-carving image forgery in JPEG images, which is addressed by our study.
METHODS
Dataset
The dataset used in this research is a custom-balanced dataset. The dataset contains 12916 images. Half of the dataset, 6458 images, are untouched JPEG images and the rest of 6458 were touched images (altered/manipulated) using seam carving with a quality of 75. The untouched images are everyday pictures of dimensions

Figure 1. Examples of untouched (on the left) and seam-carving (on the right) in JPEG image.
CNN Architecture
Figure 2 briefly shows the architecture of a simple convolutional neural network (CNN), which starts with an input dataset that mainly combines images and videos. The convolutional layer is the first step of the CNN structure that takes the input images and extracts various features. In this layer, convolution operations are conducted within the input and a filter. The output received after applying the convolutional layer is a feature map with some activation functions. The taken feature map is then fed to other layers to comprehend various other features of the input image. In most CNN architectures, the pooling layer is the next step after the convolutional layer. The pooling layer performs by decreasing the connections between layers and independently operates on the feature map to reduce the computational costs. The Pooling Layer is used as a bridge between the Convolutional Layer and the Fully Connected Layer. After the Pooling layer, the output layers are flattened and fed to the Fully connected layer — this layer is based on weights and biases and the neurons. The Fully Connected layer is used to connect the neurons between two different layers, and these layers are the last layers of the CNN structure. It is worthy of noting that Figure 2 only shows a simple architecture of a CNN, and different deep learning models come out with different structures and different layers.

Figure 2. A simple CNN Architecture.
CNN has shown tremendous success in image processing and computer vision. CNN works typically by a number of convolutional layers chained together with fully connected layers. Using two-dimensional filters, CNN computes the feature map of the given image. The layers also include max-pooling layers, which preserve significant features of the image. In CNN, the output of the last convolutional layer is kept by the dense layer by converting the layer to a vector; in other words, the last layer is converted to a vector by flattening the layer. Then softmax function is used in the dense layer by multiclass classification. Multiclass classification specifies probability values for each class.
EfficientNet architecture
Tan and Le proposed a model called EfficientNet[59]. In their research, they expanded CNN architecture by scaling models. To improve CNN architecture performance, scaling in resolution, depth, and width is required. The most common way to scale up CNN architecture was either by one of the three dimensions: depth, width, or image resolution. On the other hand, EfficientNets perform compound scaling, which scales all three dimensions while preserving a balance between all network dimensions. Compound scaling is also used on ResNet architectures. Usually, the dimensions are tested arbitrarily to improve model accuracy in practice. The authors adopted the more principled approach to scaling the model on every dimension using fixed scaling coefficients. Whenever the fixed scaling coefficients are determined, the black-box networks are scaled to reach higher accuracy. In this study, EfficientNet is represented by three dimensions: (1) depth; (2) width; and (3) resolutions; the parameter scales by every dimension as a
(1) depth =
(2) width =
(3) resolution =
where are obtained by using grid search. This equation provides a balance between computation cost and performance. Figure 3 shows the architecture model scaling in the study[59].
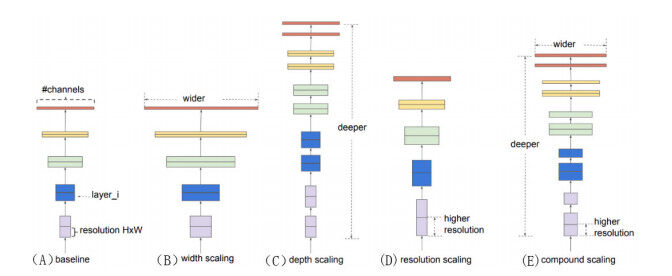
Figure 3. Model scaling in EfficientNet[59].
Starting from the baseline EfficientNet-B0, the authors in the paper[59] apply the compound scaling method to scale it up with two steps:
STEP 1: first fix
STEP 2: then fix
We compare AlexNet[63], Xception[64], ResNet50[33], VGG[34], BayarNet[35], HeNet[36], YeNet[37], LFNet[38], SRNet[39] and EfficientNet[59] models in our experiment. These models are slightly modified to make three predicted probabilities in the last layer. In the experiment, each model was trained until it was adequately incorporated in terms of training accuracy and loss for 50 epochs. Figure 4 shows the training accuracy (A) and training loss (B) for each network for 50 epochs.
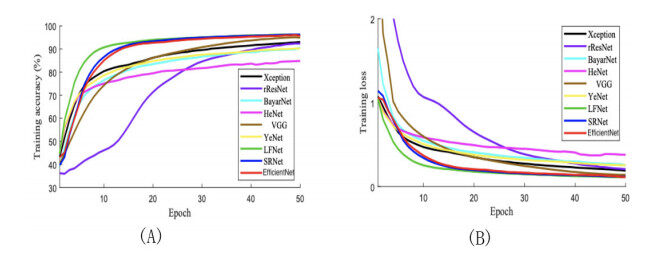
Figure 4. (A) Training accuracy and training loss (B) tendencies for each network for 50 epochs.
The learning scheduler ReduceLROnPlateau[58] is used to allow dynamic learning rate reduction based on some validation measurements. The scheduler had a factor of 0.5, a patience value of 1, and a threshold of 0.0001. The cross-entropy loss is adopted. Cross-entropy for n-classes is defined as
Where
The experiment shows that trivial progress appeared in the implementation of each model after 50 epochs. We utilized multiple classifiers in the experiments.
Evaluation metrics
In this research, evaluation of classification accuracy is measured, which is (nt/ts)100(%), where nt represents the total number of correctly predicted values and ts represents the total number of testing samples. While original and seam-insertion images were classified (the latter two are produced based on original untouched images), each class's ratio data was possessed at 1:1:1 when calculating the testing set. In addition, the receiver operating characteristic (ROC) curves were calculated to assess the performance of all the Deep Learning models. The area under AUC curve is used as a performance evaluation and the ROC curve is used to represent the relation between the true positive rate and the false positive rate. If the value of AUC is close to 1, it is considered as the model has outstanding performance, which also means it has a good measure of separability.
Performance evaluation of networks
In the performance of evaluation, we first evaluated the performance of EfficientNet and compared it with other CNNs. Table 1 shows the result of retargeting ratio parameters. The end of the table represents the classification results for a mixed test set for the sets that include 10% to 50% retargeting ratio. The accuracy values of EfficientNet for a 10% to 50% retargeting ratio are 89.12%, 98.33%, 98.67%, 99.53%, and 99.67%, respectively. The EfficientNet's classification performance in the mixed set is 98.13% which has the highest accuracy received in all CNN-based models, followed by LFNet and SRnet, which also shows excellent performance for seam-carving detection in the JPEG domains.
Performance evaluation of CNN models (%)
| Ratio | Xception | ResNet | BayarNet | HeNet | VGG | YeNet | LFNet | SRNet | EfficientNet |
| 10% | 67.34 | 74.43 | 65.73 | 65.48 | 76.23 | 78.12 | 89.26 | 87.56 | 89.12 |
| 20% | 78.45 | 80.51 | 81.87 | 81.76 | 85.32 | 85.32 | 95.32 | 95.76 | 95.33 |
| 30% | 87.67 | 88.34 | 88.23 | 88.42 | 93.29 | 93.29 | 98.12 | 98.34 | 98.67 |
| 40% | 90.67 | 90.23 | 93.42 | 92.73 | 95.76 | 95.76 | 98.43 | 99.41 | 99.53 |
| 50% | 93.43 | 93.90 | 94.92 | 93.34 | 95.64 | 95.64 | 98.79 | 99.87 | 99.67 |
| Mixed | 84.12 | 86.07 | 85.78 | 84.87 | 89.43 | 89.43 | 96.78 | 96.48 | 98.13 |
An AUC ROC is used for visualizing a model's performance between sensitivity and specificity. Sensitivity refers to the ability to correctly identify entries that fall into the positive class. On the other hand, specificity refers to the ability to correctly identify entries that fall into the negative class. Hence, an AUC ROC plot is used to identify how well the model can distinguish between classes. In our experiment, we performed three class classifications which represent original, seam inserted, and seam removed. To distinguish the images among the three classes: original (class 0), seam inserted (class 1), and seam removed (class 2), the ROC curve for each class was generated, and each AUC value for the ROC curves was calculated. For every CNN model, we instantiate a visualizer object and fit that to the training data, then generate the score by feeding in the test data.
Figure 5 illustrates the ROC curves that were computed to evaluate the performance of CNN models in detail. As illustrated in Figure 5, the ROC curve for three class generation was performed, and each AUC value for the ROC curves was calculated. ROC curves of EfficientNet, LFNet, and SRNet measurements were closer to each other, and we can conclude that EfficientNet, LFNet, and SRNet perform better than the other CNN models. The AUC values with EfficientNet are 0.991, 0.996, and 0.994 for each class, which are higher than the ones with LFNet and SRNet. The thoroughly analyzed results of Table I and Figure 5 reveal that the EfficientNet performs the best.
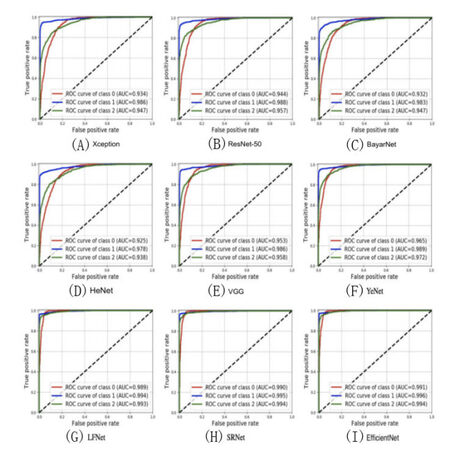
Figure 5. The ROC curve for three class generation was performed, which represents original, seam inserted, and seam removed. To distinguish the images among the three classes: original (class 0), seam inserted (class 1), and seam removed (class 2), each AUC value for the ROC curves was calculated.
We also compared the three popular optimizers: Stochastic Gradient Descent (SGD)[55], Adam (Adaptive Moment Estimation)[56], and decouples the optimal choice of weight decay factor from the setting of the learning rate for Adam (AdamW)[57] in the binary classification between untouched JPEG images and seam-carving JPEG images.
Adaptive optimizers like Adam have become a default choice for training neural networks. However, when aiming for state-of-the-art results, researchers often prefer stochastic gradient descent (SGD) with momentum because models trained with Adam have been observed not to generalize as well.
Weight decay is performed only after controlling the parameter-wise step size in Adam optimizer. The weight decay or regularization term does not end up in the moving averages and is thus only proportional to the weight itself. The authors[57] show experimentally that AdamW yields better training loss and that the models generalize much better than models trained with Adam.
We compare Adam, AdamW, and SGD optimizers in this study. We ran ten experiments under each learning algorithm with randomly selected training data set, validation dataset, and testing dataset on each experiment, the boxplots of the ten testing results under the three optimizers are given in Figure 6. The X-axis shows the three groups of optimizers, and Y-axis shows the testing accuracy (%). Our results show that the AdamW and Adam are better than SGD in this study.
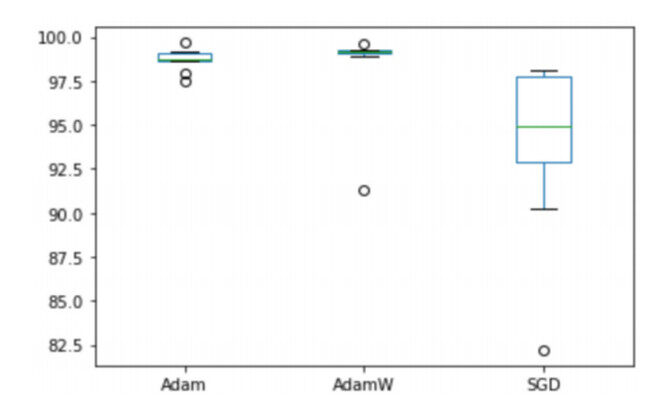
Figure 6. Boxplots of three learning algorithms with EfficientNet-B5.
We would note that AdamW and Adam perform better than SGD with EfficientNet-B5 in this study, while across different deep learning architectures and different deep learning models in a recent study in detecting COVID-19 chest X-ray images, SGD is generally superior to Adam and AdamW[26].
RESULTS
Deep learning is very successful in computer vision, e.g., object detection, image classification, but these tasks can be easily perceived by human beings. However, it is incapable for human eyes to distinguish forged images from untouched ones. To investigate the performance in detecting seam-carving-based image forgery with popular deep learning models that were used in image forensics, including image steganalysis and image forgery detection, we compared several deep learning models, and the study shows that EfficientNet performs the best, followed by SRnet and LFnet. The current study also demonstrates that the different optimizers led to different detection testing accuracy with the Efficientnet-B5. In the experiments, AdamW is generally superior to Adam and SGD. The current study also indicates that deep learning is very promising in image forensics that is hardly discernable to human perceptions.
DECLARATIONS
Authors' contributions
Performed the comparison study of the nine deep learning models and drafted the paper: Celebi NH
Helped in producing a part of the data and assisted in the draft: Hsu TL
Supervised the study, assisted in the experiments, and the draft: Liu QZ
Availability of data and materials
Dataset will be availables at https://github.com/Frank-SHSU/seam_carving-image-dataset
Financial support and sponsorship
None.
Conflicts of interest
All authors declared that there are no conflicts of interest.
Ethical approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Copyright
© The Author(s) 2022.
REFERENCES
1. Birajdar GK, Mankar VH. Digital image forgery detection using passive techniques: a survey. Digital Investigation 2013;10:226-45.
2. Qureshi MA, Deriche M. A bibliography of pixel-based blind image forgery detection techniques. Signal Processing: Image Communication 2015;39:46-74.
3. Ke Y, Shan Q, Qin F, Min W, Guo J. Detection of seam carved image based on additional seam carving behavior. IJSIP 2016;9:167-78.
5. Sarkar A, Nataraj L, Manjunath BS. Detection of seam carving and localization of seam insertions in digital images, Proc. 11th ACM Workshop on Multimedia and Security (MM&Sec'09), NY, USA, pp. 107-116, 2009.
6. Yin T, Yang G, Li L, Zhang D, Sun X. Detecting seam carving based image resizing using local binary patterns. Computers & Security 2015;55:130-41.
7. Liu Q. An approach to detecting JPEG down-recompression and seam carving forgery under recompression anti-forensics. Pattern Recognition 2017;65:35-46.
8. Lu M, Niu S. Detection of image seam carving using a novel pattern. Comput Intell Neurosci 2019;2019:9492358.
10. Jassim S, Asaad A. Automatic detection of image morphing by topology-based analysis. In 2018 26th European Signal Processing Conference (EUSIPCO), pages 1007–1011. IEEE, 2018.
11. Neubert T. Face Morphing Detection: An Approach Based on Image Degradation Analysis. In: Kraetzer C, Shi Y, Dittmann J, Kim HJ, editors. Digital Forensics and Watermarking. Cham: Springer International Publishing; 2017. pp. 93-106.
12. Popescu A, Farid H. Exposing digital forgeries by detecting traces of resampling. IEEE Trans Signal Process 2005;53:758-67.
13. Ryu S, Lee H. Estimation of linear transformation by analyzing the periodicity of interpolation. Pattern Recognition Letters 2014;36:89-99.
14. Guillemot C, Le Meur O. Image inpainting : overview and recent advances. IEEE Signal Process Mag 2014;31:127-44.
15. Salloum R, Ren Y, Jay Kuo C. Image Splicing Localization using a Multi-task Fully Convolutional Network (MFCN). Journal of Visual Communication and Image Representation 2018;51:201-9.
16. Cozzolino D, Poggi G, Verdoliva L. Efficient Dense-Field Copy-Move Forgery Detection. IEEE Trans Inform Forensic Secur 2015;10:2284-97.
17. Jian Li, Xiaolong Li, Bin Yang, Xingming Sun. Segmentation-based image copy-move forgery detection scheme. IEEE Trans Inform Forensic Secur 2015;10:507-18.
18. Gong Q, Shan Q, Ke Y, Guo J. Detecting the location of seam and recovering image for seam inserted image. JCM 2018;18:499-509.
19. Li Y, Xia M, Liu X, Yang G. Identification of various image retargeting techniques using hybrid features. Journal of Information Security and Applications 2020;51:102459.
20. Liang Z, Yang G, Ding X, Li L. An efficient forgery detection algorithm for object removal by exemplar-based image inpainting. Journal of Visual Communication and Image Representation 2015;30:75-85.
21. Wu Q, Sun SJ, Zhu W, Li GH, Tu D. Detection of digital doctoring in exemplar-based inpainted images. In Machine Learning and Cybernetics, 2008 International Conference on. 2008;3: 1222-6.
22. Farid H. Exposing Digital Forgeries From JPEG Ghosts. IEEE Trans Inform Forensic Secur 2009;4:154-60.
23. Luo W, Huang J, Qiu G. JPEG Error Analysis and Its Applications to Digital Image Forensics. IEEE Trans Inform Forensic Secur 2010;5:480-91.
24. Bayar B, Stamm MC. A deep learning approach to universal image manipulation detection using a new convolutional layer. In Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security. 2016: 5-10.
25. Rao Y, Ni JQ. A deep learning approach to detection of splicing and copy-move forgeries in images. In Information Forensics and Security (WIFS), International Workshop on. 2016: 1–6.
26. Liu Q, Chen Z, Liu HC. A comparison study to detect COVID-19 X-ray images with SOTA deep learning models. Proceedings of the 1st Workshop on Healthcare AI and COVID-19. ICML 2022;184:146-153.
27. Shi YQ, Chen C, Chen W. A Markov Process Based Approach to Effective Attacking JPEG Steganography. In: Camenisch JL, Collberg CS, Johnson NF, Sallee P, editors. Information Hiding. Berlin: Springer Berlin Heidelberg; 2007. pp. 249-64.
28. Fillion C, Sharma G. Detecting content adaptive scaling of images for forensic applications. Media Forensics and Security, SPIE Proc., p. 75410, 2010.
29. Chang W, Shih TK, Hsu H. Detection of seam carving in JPEG images. in: Proceedings of the 2013 International Joint Conference on Awareness Science and Technology and Ubi-media Computing, pp 632-638, 2013.
30. Wattanachote K, Shih TK, Chang W, Chang H. Tamper Detection of JPEG Image Due to Seam Modifications. IEEE Trans Inform Forensic Secur 2015;10:2477-91.
31. Fridrich J, Kodovsky J. Rich models for steganalysis of digital images. IEEE Trans Inform Forensic Secur 2012;7:868-82.
32. Liu Q. Exposing seam carving forgery under recompression attacks by hybrid large feature mining. 23rd Int. Conf. on Pattern Recog. (ICPR), pp. 1036-1041, 2016.
33. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016: 770-778.
34. Nam SH, Park J, Kim D, Yu IJ, Kim TY, Lee HK. Two stream network for detecting double compression of h. 264 videos, in 2019 IEEE International Conference on Image Processing (ICIP). IEEE, 2019, pp. 111–115.
36. He P, Jiang X, Sun T, Wang S, Li B, Dong Y. Frame-wise detection of relocated I-frames in double compressed H.264 videos based on convolutional neural network. Journal of Visual Communication and Image Representation 2017;48:149-58.
37. Ye J, Shi Y, Xu G, Shi Y. A Convolutional Neural Network Based Seam Carving Detection Scheme for Uncompressed Digital Images. In: Yoo CD, Shi Y, Kim HJ, Piva A, Kim G, editors. Digital Forensics and Watermarking. Cham: Springer International Publishing; 2019. pp. 3-13.
38. Ono Y, Trulls E, Fua PV, Yi KM. (2018). LF-Net: Learning Local Features from Images. ArXiv, abs/1805.09662.
39. Boroumand M, Chen M, Fridrich J. Deep Residual Network for Steganalysis of Digital Images. IEEE Trans Inform Forensic Secur 2019;14:1181-93.
40. Liu Q. An Improved Approach to Exposing JPEG Seam Carving Under Recompression. IEEE Trans Circuits Syst Video Technol 2019;29:1907-18.
41. Diallo B, Urruty T, Bourdon P, Fernandez-maloigne C. Robust forgery detection for compressed images using CNN supervision. Forensic Science International: Reports 2020;2:100112.
42. Majumder MTH, Islam AAA. A tale of a deep learning approach to image forgery detection, in 2018 5th International Conference on Networking, Systems and Security (NSysS). IEEE, 2018, pp. 1–9.
43. Yao H, Xu M, Qiao T, Wu Y, Zheng N. Image Forgery Detection and Localization via a Reliability Fusion Map. Sensors (Basel) 2020;20:6668.
44. Du M, Pentyala S, Li Y, Hu X. Towards generalizable deepfake detection with locality-aware autoencoder, in Proceedings of the 29thACM International Conference on Information & Knowledge Management, 2020, pp. 325–334.
45. Thakur A, Jindal N. Machine learning based saliency algorithm for image forgery classification and localization, in 2018 First International Conference on Secure Cyber Computing and Communication (ICSCCC) IEEE, 2018, pp. 451–456.
46. Muhammad G, Al-hammadi MH, Hussain M, Bebis G. Image forgery detection using steerable pyramid transform and local binary pattern. Machine Vision and Applications 2014;25:985-95.
47. Warif NBA, Idris MYI, Wahab AWA, Ismail NN, Salleh R. A comprehensive evaluation procedure for copy-move forgery detection methods: results from a systematic review. Multimed Tools Appl 2022;81:15171-203.
48. Le-tien T, Phan-xuan H, Nguyen-chinh T, Do-tieu T; The authors are with the Department of Electrical and Electronics Engineering, University of Technology, National University of Ho Chi Minh city, Vietnam. Image forgery detection: a low computational-cost and effective data-driven model. IJMLC 2019;9: 181-8.
49. Han J, Gevers T. MMD Based Discriminative Learning for Face Forgery Detection. In: Ishikawa H, Liu C, Pajdla T, Shi J, editors. Computer Vision - ACCV 2020. Cham: Springer International Publishing; 2021. pp. 121-36.
50. Aneja S, Nießner M. Generalized zero and few-shot transfer for facial forgery detection, arXiv preprint arXiv: 2006.11863, 2020.
51. Bourouis S, Mashrgy MA, Bouguila N. Bayesian learning of finite generalized inverted Dirichlet mixtures: application to object classification and forgery detection. Expert Systems with Applications 2014;41:2329-36.
52. Cao S, Zou Q, Mao X, Wang Z. Metric learning for anti-compression facial forgery detection, arXiv preprint arXiv: 2103.08397, 2021.
53. Srivastava V, Yadav SK. Frequency based edge-texture feature using Otsu's based enhanced local ternary pattern technique for digital image splicing detection. Bulletin EEI 2021;10:3147-55.
54. Zhang R, Ni J. A dense u-net with cross-layer intersection for detection and localization of image forgery, in Proc. 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2982–2986.
55. Bottou L. On-line Learning and Stochastic Approximations. In: Saad D, editor. On-Line Learning in Neural Networks. Cambridge University Press; 2010. pp. 9-42.
57. Loshchilov I, Hutter F. (2019). Decoupled Weight Decay Regularization. ICLR (Poster) 2019, arXiv: 1711.05101v3.
58. "Torch. optim¶, " torch. optim - PyTorch 1.11.0 documentation. [Online]. Available from: https://pytorch.org/docs/stable/optim.html [Last accessed on 9 Aug 2022].
59. Tan M, Le QV. (2019). EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. ArXiv, abs/1905.11946.
60. Nam S, Ahn W, Yu I, Kwon M, Son M, Lee H. Deep Convolutional Neural Network for Identifying Seam-Carving Forgery. IEEE Trans Circuits Syst Video Technol 2021;31:3308-26.
61. Lu M, Niu SZ. (2019), Detection of Image Seam Carving Using a Novel Pattern, Computational Intelligence and Neuroscience, vol. 2019, Article ID 9492358, 15 pages, 2019.
62. Senturk ZK, Akgun D. Seam carving based image resizing detection using hybrid features. Tehnicki Vjesnik 2017;24:1825-1832.
63. Krizhevsky A, Sutskever I, Hinton GE. ImageNet classification with deep convolutional neural networks. In NIPS, pp. 1106–1114, 2012.
Cite This Article
Export citation file: BibTeX | RIS
OAE Style
Celebi NH, Hsu TL, Liu Q. A comparison study to detect seam carving forgery in JPEG images with deep learning models. J Surveill Secur Saf 2022;3:88-100. http://dx.doi.org/10.20517/jsss.2022.02
AMA Style
Celebi NH, Hsu TL, Liu Q. A comparison study to detect seam carving forgery in JPEG images with deep learning models. Journal of Surveillance, Security and Safety. 2022; 3(3): 88-100. http://dx.doi.org/10.20517/jsss.2022.02
Chicago/Turabian Style
Celebi, Naciye Hafsa, Tze-Li Hsu, Qingzhong Liu. 2022. "A comparison study to detect seam carving forgery in JPEG images with deep learning models" Journal of Surveillance, Security and Safety. 3, no.3: 88-100. http://dx.doi.org/10.20517/jsss.2022.02
ACS Style
Celebi, NH.; Hsu T.L.; Liu Q. A comparison study to detect seam carving forgery in JPEG images with deep learning models. J. Surveill. Secur. Saf. 2022, 3, 88-100. http://dx.doi.org/10.20517/jsss.2022.02
About This Article
Copyright

Data & Comments
Data


 Cite This Article 15 clicks
Cite This Article 15 clicks

 Like This Article 3
likes
Like This Article 3
likes







Comments
Comments must be written in English. Spam, offensive content, impersonation, and private information will not be permitted. If any comment is reported and identified as inappropriate content by OAE staff, the comment will be removed without notice. If you have any queries or need any help, please contact us at support@oaepublish.com.