
Learning and unlearning from disasters: an analysis of the Virginia Tech, USA shooting and the Lion Air 610 Airline crash


Abstract
Aim: The aim of this paper is to explore whether and how far organisations learn from failures.
Methods: The paper reviews the current literature about organisational learning and theories of learning from failures, where learning here implies change of practice, and use of modelling techniques to inform recommendations to prevent repetition of similar incidents. Further, it analyses two case studies related to aspects of security and safety: the Virginia Tech Shooting in 2007 and the Lion Air 610 crash in 2018. Both case studies address the concept of learning from failures. In doing so, an analysis of the root causes and vulnerabilities through the methods of Fault Tree Analysis and Reliability Block Diagram is conducted to identify lessons to be learned.
Results: Findings are intended to stimulate organisational learning and improve organisational processes to mitigate disasters from happening again.
Conclusion: The value of this study is that aspects of learning and unlearning from failures have been identified for the cases used. Expectation for future studies is to extend the proposed methodology to other cases in the fields of surveillance, security and safety.
Keywords
Introduction
Failures are often associated with negative implications and illustrated to be something that should be avoided in organisations. However, it has been identified that failures can help improve organisational learning and strengthen an organisation’s resilience[1-4]. Further, it is argued that organisations learn more from failures than successes[5]. However, learning from failures is not always achieved by organisations due to factors such as denial of failure, issues of ineffective communication and information sharing, status quo and lack of corporate responsibility[6]. When failures are not detected in time, they can cause a chain reaction resulting in a major failure or disaster. Within organisations, these major failures are often seen as Black Swans as their occurrence is low, but their impact is severe[7]. According to Fortune and Peters[8], failures that have such a destructive impact that they receive widespread media attention and investigation are considered disasters. These impacts are not limited to a number of fatalities and casualties but also related to the wider influence on for example economies, policies and communities. Knight and Pretty’s[9] seminal work demonstrated a clear link between an organisation’s positive handling of a failure and the potential increase in cumulative annual returns, suggesting a further financial imperative to encourage organisations to better engage with learning from failure. The aim of this paper is to explore whether and how far organisations learn from failures. The main contributions of this paper are two-fold: First, we demonstrate that a common modelling set of tools can be applied to completely different disasters chosen from the two domains of safety and security. Second, we present a taxonomy of failures classification and the role of mental modelling in learning from failures.
Methods
Following the Introduction, the paper reviews the current literature on organisational learning, learning and unlearning from failures as well as explaining failure theories. The paper then analyses two case studies related to aspects of security and safety: the Virginia Tech, USA shooting in 2007 and the Lion Air 610 crash in 2018. Both cases have been chosen to compare efficient learning from failures versus inefficient learning from failures. Further, they have been selected to demonstrate the framework of learning from failures introduced by Labib and Read[1], which addresses three aspects: the aspect of feedback from users to design (i.e., change the status quo), the incorporation of failure analytical tools (new mental models) and the generic lessons learned (i.e., isomorphic learning), highlighting the wider applicability of the approach, independent of industry or event type. The paper concludes with a discussion and a summary.
The case studies are following the framework of Labib[10] by first introducing the case and sequences that resulted in the disaster. After the technical cause and logic of the failure is assessed and consequences addressed, methods such as the Fault Tree Analysis (FTA) and the Reliability Block Diagram (RBD) are used to identify the causes and the vulnerability factor. The case studies are concluded by recommendations and identification of generic lessons to support organisational learning from failure.
Organisational learning and unlearning
Learning is an important aspect of life as it is can stimulate change and improve actions through better understanding and knowledge[11]. This approach not only influences individuals but also organisations. Organisational learning implements the standard definition and applies it to a wider context. Since the 1980s, the idea of organisational learning has flourished, with numerous definitions and studies into the concept[12]. According to Toft and Reynolds[13], organisational learning is seen as a process in which individuals in an organisation continuously reflect upon and reinterpret their working environment and the experiences encountered in order to improve actions. This definition was supported by Madsen and Desai[5] who defined organisational learning as “any modification of an organization’s knowledge occurring as a result of its experience”. To take this definition a step further, it is argued that organisational learning should not only focus on own experiences but also those of others. Learning from others’ experiences is defined as vicarious learning[5] or isomorphic learning[13]. Both aspects of learning not only positively influence organisational processes but also enhance organisational resilience and can be an important catalyst in organisational change, as observed by Weinzimmer and Esken[14].
Whilst understanding of the concept developed, a desire to maximise learning for organisations began and, from this, barriers to learning and enablers to learning started to be explored. Debate regarding whether learning from failure or success offered greater benefit started to occupy some of the research within organisational learning and, from this, the identification of second-order effects and ultimately organisational unlearning evolved[15].
Definitions of organisational unlearning could be argued to revolve around “intentionality”, that is, whether the organisation intentionally forgot existing knowledge or did so unintentionally. It is here that Tsang and Zahra’s[16] insight is useful for organisations, as they clearly defined organisational unlearning as “deliberate discarding of routines”[16] (p. 1437), arguably providing a more useful interpretation for organisations.
Within the context of organisational failures, the concept of learning and unlearning from events becomes even more important, in order to try to prevent a recurrence of the negative incident or minimise the chance for it to happen again. This paper now turns to the specific aspects of learning and unlearning from failures.
Learning and unlearning from failures
In the work of Madsen and Desai[5], they argued that organisations tend to learn more from failures than successes. However, they also stated that success commonly stabilises organisations, whereas failures require a change of the status quo and challenge an organisation. This latter point was supported by Levitt and March[12] who identified that organisations tend to be more adaptable to learning from successful outcomes than negative actions that should have been avoided. In the work of Weinzimmer and Esken[14], they identified the difference between learning from successes, which requires an organisation to “exploit” this new knowledge, and learning from failures, which they argued requires organisations to engage in deeper “exploration” of the learning opportunity and ultimately offers greater potential benefits, although it is more painful for the organisation. Kunert[17] (p. 19) suggested that “while success and orderliness will arouse little drive to change existing routines, failure is more likely to foster the willingness and urgency to change, and, thus, stimulate action”. Sitkin[2] agreed by stating that failure improves learning and resilience. In comparison, Toft and Reynolds[13] identified that learning and respective decision making should address both successes and failures.
Learning from failures mainly depends on the failure being detected and appropriately analysed[8]. Further, organisations often focus on evidence that supports their existing beliefs rather than accepting explanations that challenge the status quo of their companies[6], something that can be a key driver in organisational failure.
Thus, this discussion brings us to the following important questions: Under which conditions are organisations reluctant to learn from failures? How should we motivate them to learn from failures? What is organisational unlearning from failures and how can this help us to better support organisations?
Conditions potentially resulting in reluctance to learn from failure
When an organisational failure occurs due to poor conduct, omission or a need to accept responsibility, organisations can sometimes be seen to engage less willingly in the learning process. Similarly, if a mistake-intolerant culture exists, organisations will be unlikely to engage meaningfully in learning from failure[14]. It could therefore be suggested that failures that include elements of organisational culpability or reputation risk, particularly due to human failure, could potentially create reluctance to engage and learn from failure; initial responses from BP’s CEO to the Deepwater Horizon incident are an example of this[18,19].
How to motivate engagement with learning from failure
Organisational learning is seen by many as a strategic tool for organisational success and to enhance organisations’ efficiency[20]. Furthermore, the importance of Knight and Pretty’s[9] work is again underlined here through the clear demonstration of the link between how well organisations managed failures and their financial standing. By encouraging organisations to engage with such thinking, providing examples and by supporting use of simulations and scenarios, organisations should begin to understand the value of such learning.
What is unlearning from failures and how can it benefit organisations?
Unlearning from failures can be conceptualised at three levels. Labib[21] used the theoretical lens from Mahler[22] of categories of organisations unlearning to illustrate how this applies to disasters. In Mahler’s view, there are three types of lessons that cause unlearning for organisations: (1) lessons not learned; (2) lessons learned only superficially; and (3) lessons learned and then subsequently unlearned. Labib[21] then provided three examples from disasters to illustrate how each of these types of unlearning has occurred.
There are plenty of examples where similar types of incidents keep occurring and repeated incidents occur because organisations have no memory since there are plenty of personnel changes that result in a “brain drain”, using Kletz’s[23] term. Our proposed modelling, as we will show below, provides a concise visual representation of the causal factors as a simplified mental model, and hence they are easier to remember rather than reading narratives of incident reports that usually run hundreds of pages. Such modelling approach also helps to establish the relationships among the causal factors, and hence provides a visual assessment of the vulnerability (weak or blind spots) in the system, thus informing our analysis of safety barriers.
Theories of failure
According to Labib[10], learning or unlearning from failure can be linked to a wide range of theories. Organisations can learn from failures through case studies or storytelling. However, they might be confronted with the concept of narrative fallacy[7]. This theory indicates that humans often search for explanations to the point where they manufacture them. Two other approaches address aspects of decision making. Organisations can either be too risk-averse or too risk-seeking. This is perfectly illustrated by the Swiss Cheese Model (SCM) introduced by Reason[24]. This conceptual model provides a simple illustration of the function in place where, if all guards fail, the whole system fails. The basic idea of SCM is that the layers/slices of cheese represents numerous system barriers that exist in the organisation in the form of procedures, check-lists and human checks for preventing hazards, while defects or loopholes in the system are represented by holes in the cheese layers. This model visualises incidents as the result of accumulation of multiple failures in barriers, or defences, represented as an alignment of holes in successive slices; hence, it is a simplified model to show the dynamics of accident causation. In other words, the failure occurred due to alignment of holes or simultaneous failures (loopholes in the system) of safety barriers. By safety barriers, this is analogous to the body’s auto-immune system. More details about SCM and its evolution and limitations can be found in[25]. The model indicates cheese slices as barriers of protection concluding that the number of cheese slices identifies the level of risk aversion. Such modelling is easy to understand but its simplicity has also been criticised in that it does not represent adequately the relationship between different causal factors. Our proposed approach is intended to address this by providing more insight into causal relationships. Thus, the FTA, on the other hand, works its way to understand, or predict, what can cause the final unwanted event to happen, by working from the undesired event at the top of the FTA, and drilling down to the most basic events that are associated together through logic gates to examine the relationships among causal factors.
Further, organisations can learn from specific and/or generic lessons of disasters. They can decide to adopt either the approach of Normal Accident Theory (NAT) or high-reliability theory. NAT, which was introduced by Perrow[26], claims that complexity and lack of prevention measures will unavoidably result in a disaster. Thus, the main claim of this argument is that accidents cannot be predicted or prevented and hence are “normal” and unavoidable. In contrast, the approach of High-Reliability Organisation (HRO) theory states that organisations can contribute to the prevention of disasters[27]. Hence, the emphasis here is not how accidents happen, but what successful organisations do to promote and ensure safety in complex systems. NAT and HRO have created two schools of thought in the literature related to failure theories. For a comprehensive and a balanced account of both schools of thought, the reader is directed to the works of Saleh et al.[28] and Rijpma[29].
Rationale and methods applied
This paper focuses on two case studies of different backgrounds; one relates to security and the other to safety. The first case analyses the Virginia Tech Shooting in 2007 relating to failure management from a security perspective. As the incident has been extensively researched and highly influenced policymakers such as universities and government in the U.S. in improving regulations, policies, and laws[30-33], it is considered as a good example of learning from failure. The second case study concerns the Lion Air 610 airplane crash, which occurred in October 2018. This case study was chosen due to its current relevance and relation to aspects of safety. Further, the case study reflects on aspects of not fully learning from failures. This poor example of organisational learning, or “unlearning”, is evident by the subsequent crash of Ethiopian Air shortly afterwards, which ultimately led Boeing to decide to halt the production of this type of aircraft. However, it needs to be acknowledged that the case studies are limited due to being secondary information collected by others and potentially being biased.
The two methods applied in this paper are FTA and RBD. Both methods complement each other as the RBD is constructed based on the structure of the FTA[10]. Combining both methods, as a hybrid model approach, can help to identify failures leading to a disaster, optimise the allocation of resources to address safety gaps and thereby mitigate consequences for future disasters[10].
An FTA identifies, models and evaluates the unique interrelationship of events leading to: (1) failure; (2) undesired events; or (3) unintended events. Those events are on the top of the FTA resulting from the input events indicated in the fault tree. Events are connected by “AND” and “OR” gates. An “OR” gate indicates that one or more events must occur to trigger the output event. In comparison, an “AND” gate is used when all failures indicated in connection with the output event must occur at the same time. The RBD gathers the events from the “AND” gate identified in the FTA into a parallel structure and the “OR” gate into a series one[10]. This method is used to identify vulnerabilities and gaps.
Addressing vulnerabilities can be an iterative and recursive process to help better understand and modify the original modelling in the form of a fault tree. This kind of analysis can be achieved either algebraically using the operational research method of minimum cut sets (a cut set is a combination of failure events, causing the top event in a fault tree) or by simply examining all possible failure scenarios of boxes in the RBD that will cause “cut-through” of the model. Such exercises build up critical mental problem-solving muscles, instead of simply reading a narrative of a report. It also helps to examine the logical combination of safety barriers that can mitigate against potential similar hazard.
Since fault trees are hierarchical structures, where the top of the tree is the undesirable incident (the disaster), and the bottom events are causal factors (root causes), there has been very little research on the middle levels of the hierarchical structure, especially the level just below the top event. This is particularly important as framing the problem dictates how the scope of the analysis will be developed into causal factors and subsequent recommendations. It has been proposed that the middle part of the fault tree can resemble the remit of the middle managers in humanitarian logistics organisations in terms of learning from rare events[34]. In addition, there has been a variation in terms of ways of classifying reasons of failure. For example, the factors can be grouped into “direct” and “indirect” causes such as the work of Labib and Read[1] in the analysis of Hurricane Katrina disaster. The same approach is followed in this paper as it helps to focus on both short and long terms recommendations. In addition, such taxonomy helps to realise both single- and double-loop learning.
Argyris (p. 68)[11] proposed the concept of single-loop learning, which can be defined as: “an error is detected and corrected without questioning or altering the underlying values of the system”. It can be argued that this is related to the “direct” causes in an FTA model. Conversely, Argyris (p. 68)[11] defined double-loop learning as: “mismatches are corrected by first examining and altering the governing variables, and then reviewing the actions”. This can be attributed to be among the “indirect” causes in the FTA modelling. Triple-loop learning has also been proposed in the literature, but this is beyond the scope of our paper. Other variations to classify failures can be as sociological and technical, or human and technology related issues.
Case study 1: Virginia Tech Shooting, USA, 2007
Background
One of the deadliest shootings in US history took place on 16 May 2007 at Virginia Tech University, Blacksburg. The shooting comprised two attacks that took place in two different locations on campus, which are illustrated in Figure 1[35]. The first shooting took place at 07:15 at West Ambler Johnston Hall dormitory, killing two people. Since the police associated the shooting with a domestic incident and assumed the attacker had already left campus, they did not shut down the campus[35]. About two and a half hours later, the gunman started the second shooting in Norris Hall building. Referring to witnesses, the gunman entered various classrooms and started randomly shooting at everyone[35]. As the gunman realised that the police were rushing into the building, he shot himself.
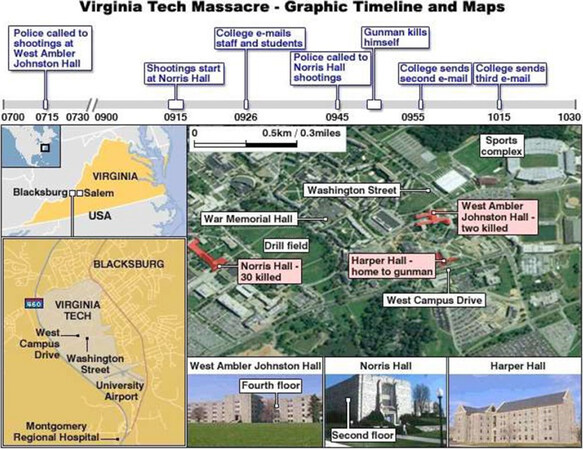
Figure 1. Graphic timeline of the incident and campus map (source: ref.[35])
Logic and technical cause of failure
As this incident has been fully investigated and to reduce biased information, the causes of failure identified have been obtained from the amended Review Panel Report[36] of the Virginia Tech Shooting (2009). The failures have been identified as followed:
Since his childhood, Cho exhibited mental health issues and received psychiatric treatment and counselling for selective mutism and depression. His mental instability worsened during his junior year at university as the university’s care team failed to provide support to Cho.
After he mentioned suicidal remarks to his roommates, his mental health was evaluated by psychologists. However, this was done inadequately resulting in insufficient treatment of Cho.
With his history of mental health instability, he would not have been allowed by federal law to purchase the two guns which he used in the shooting. However, his data were never entered into the federal database used for background checks when purchasing firearms.
There were communication errors among the university entities involved with Cho’s situation and the incidents encountered by other students and faculty. Further, laws concerning the privacy of health and education records have been misinterpreted.
Students and staff were not notified of the first shooting due to a misinterpretation of the incident and ineffective warning systems in place.
The university emergency plan did not include scenarios of a shooting and the assignment of a threat assessment team.
The university had insufficient security systems such as cameras in dormitories and entrances to buildings as well as locks on classrooms.
Consequences
Twenty-seven students and five teachers were killed, and 17 people wounded by 23-year-old Virginia Tech student Seung-Hui Cho[35,36].
FTA and RBD
The FTA illustrated in Figure 2 identifies the direct causes and contributing factors leading to the Virginia Tech Shooting. The equivalent RBD is then cited in Figure 3, where every OR is series and every AND is parallel structure. The first direct cause defined is gunman Cho. Insufficient treatment, worsening mental health and a lacking supporting system were linked with an AND- gate to demonstrate their almost simultaneous occurrence. The insufficient treatment resulted from an inadequate evaluation of his mental health and lack of reporting. Another direct cause is linked to Cho’s ability to purchase the guns due to reporting failures about the unstable mental health of Cho and a gap in gun laws. The third direct cause relates to the university and its lack of internal communication, the misinterpretation of the mental health and education laws, as well as the overall insufficient evaluation of Cho’s situation. The contributing factors are linked with an AND-gate addressing the deficiency in responding to the incident and the lack of security systems around campus. Lacking information in the emergency plan, the decision to not notify staff and students as well as hierarchical issues between the police and the university all influenced the overall response to the incident. Causes 10 and 11 relate to the inefficient emergency plan. Causes 12 and 13 linked with an OR-gate lead to the decision to not notify people on campus.
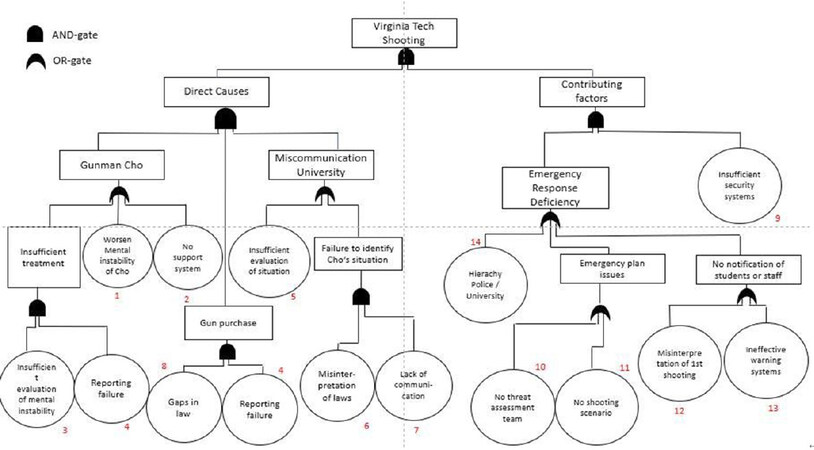
Figure 2. Fault Tree Analysis of the Virginia Tech Shooting
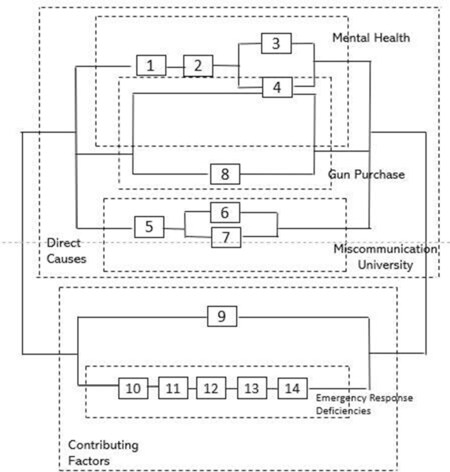
Figure 3. Reliability Block Diagram of the Virginia Tech Shooting
Recommendations and generic lessons
Lack of information sharing, misinterpretation and insufficient evaluation of situations, as well as lack of communication, can be considered the main causes for the shooting. Universities and learning facilities should promote the sharing of knowledge internally, in particular when it concerns safety and health. Policies and laws should be carefully reviewed and unclarities identified and addressed. Further, learning institutions should allocate more resources to their care teams to improve support of students struggling with mental health issues. Emergency plans should be reviewed and updated regularly. They should implement a wide range of “what if” scenarios such as shootings. In addition, introducing a wide variety of communication channels and connecting them via one system can help to effectively warn students and staff in case of incidents.
Case study 2: Lion Air 610 Airplane Crash, 2018
Background
On 29 October 2018, a Boing Max 737-8 operated by Lion Air was scheduled to fly from Jakarta to Pangkal Pinang, as illustrated in Figure 4[34].
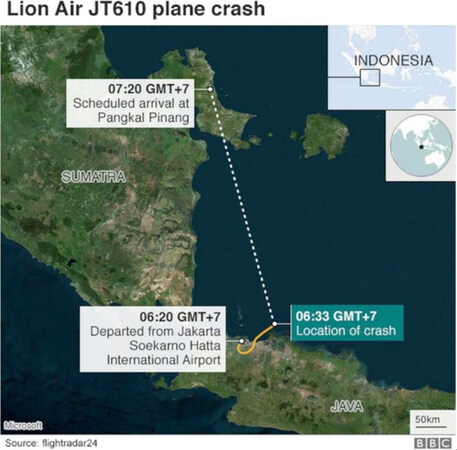
Figure 4. Expected route of Lion Air Flight 610 and the location of the crash (source: ref.[37])
The scheduled departure time for flight LNI610 was 05:45. Two pilots, six crew members, and 181 passengers were on board the airplane[38]. Shortly after its departure, the pilots faced problems with indicating the altitude and the airspeed of the plane due to critical sensors registering different readings[39]. To identify the correct information, they contacted air traffic control. Shortly after, the airplane dropped over 700 feet as the aircraft’s safety system MCAS, which was triggered by the falsified information of altitude, had forced the plane to nose down[39]. The pilots were able to correct and recover from the drop. However, the MCAS continued to push the plane’s nose down even after pilots proceeded with counteractions. The plane went up and down more than a dozen times before disappearing from the radar[39].
Logic and technical cause of failure
As the investigation of this disaster is still ongoing and the final report is due to be released in August this year, the technical causes were based on the Preliminary Aircraft Accident Investigation Report (2018) of the Indonesian Transport Committee (KNKT)[38] and news articles related to the subject. The causes identified can be summarised as follows:
(1) The Angle of Attack (AoA) sensor falsely indicated that the airplane’s nose was too high and that the airplane was stalling. The information obtained by the AoA sensor triggered the automatic safety system Maneuvering Characteristics Augmentation System (MCAS), which forced the airplane’s nose down[39].
(2) The MCAS overrode the pilots’ response as they were trying to correct the problem by lifting the plane’s nose back up[38].
(3) Pilots were not aware of the existence of MCAS. They seemed to have not received any training for this feature and no information was added in the manual[39].
(4) The airplane did not have the optional warning light that would have indicated the problem’s root. Issues with previous flights of the airplane and response actions by pilots to overcome those have not been carefully evaluated and communicated properly[35].
(5) The MCAS had a poor system redundancy by being able to be triggered by a single sensor, even though there are two AoA sensors on every airplane[40].
Consequences
The airplane crashed at about 5000 feet with a speed of 450 miles per hour into the Java Sea[39]. All people on board died in the airplane crash. It is the second deadliest airplane accident in Indonesia.
FTA and RBD
The FTA illustrated in Figure 5, and its equivalent RBD in Figure 6 identify the direct and indirect causes leading to the Lion Air 610 crash, and the overall vulnerability analysis. A technical error was defined as the first direct cause. The AoA sensor providing wrong information about altitude and speed as well as triggering the MCAS, the MCAS overriding the pilots’ response and the missing optional warning light were all indicated as the root causes for the technical failure of the machine. As they occurred simultaneously (and they were both needed and sufficient for the outcome to be realised), they were linked with an AND-gate. Another failure included the response of the pilots whose countermeasures were inefficient. Further, they failed to identify the problem because MCAS was a new feature, pilots did not receive any training on MCAS and the handbook was not updated. Indirect causes are linked to failures of the operator Lion Air and the manufacturer Boing. Failures by the operator included that the airline did not evaluate the previous issues in relation to the AoA sensor and the MCAS as well as the missing internal communication. On the other side, failures in the software and poor system redundancy resulted in the malfunctioning of the MCAS. Additionally, simulations did not include potential failure scenarios. These causes are linked to Boing.
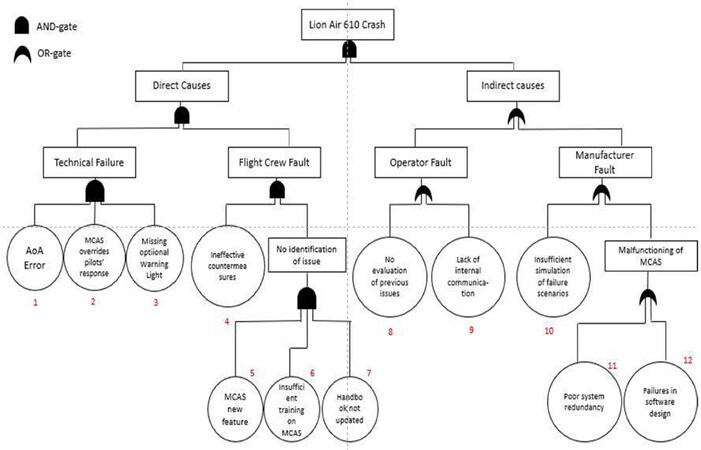
Figure 5. Fault Tree Analysis of the Lion Air 610 airplane crash
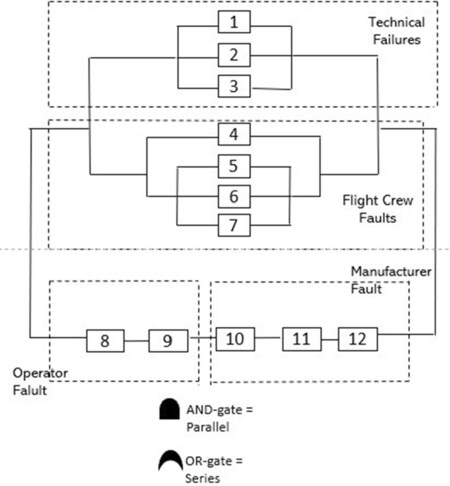
Figure 6. Reliability Block Diagram of Lion Air 610 airplane crash
Recommendations and generic lessons
The main lessons to be learned are that lack of communication and lack of training are often the root causes of airplane crashes. By informing and training pilots appropriately about new features implemented in the airplanes, failures in responding can be reduced. Further airplane manuals should be updated regularly. By sharing information on near misses internally and improving communications, airlines can help to mitigate disasters.
In addition, airlines should carefully consider the optional safety features that can be purchased from the manufacturers for a relatively low cost. Manufacturers such as Boing should carefully evaluate potential failures of software and design before implementing new features. To increase the redundancy of the MCAS, Boeing should link the feature to two sensors instead of just one. Depending on the outcomes of investigations, airlines and authorities should work collaboratively to address the safety of passengers and flight crews - even if that means the grounding of airplanes and financial losses.
Discussion
Implementing the FTA and RBD in the analysis of the two case studies in this paper helped to understand the root causes and to recognise the vulnerability gaps. In a wider context, the methods identified similarities between the two cases in relation to failures associated with the disasters. These include failures in information sharing, communication and lack of knowledge. Further, both cases presented unlearning from near misses before the disasters occurred. However, the cases differ in their level of learning from the disasters. In the case of the Virginia Tech Shooting, the failures have been detected, analysed and lessons learned implemented nationwide through updated regulations, laws and policies. However, in the case of the Lion Air 610 crash, the failures have only been partly detected as investigations have not been concluded yet. Hence, the organisations involved have the just begun with learning from the failure. This is also reflected in the crash of the Ethiopian Airlines last month (March, 2019), which was identified to have similar causes of failure seemingly not having been completely addressed yet.
Regarding the case of the Virginia Tech Shooting, the RBD identified gaps in the emergency response. Referring to the Swiss Cheese Model, it can be indicated that a lack of barriers resulted in the emergency response to be the most vulnerable part of the system. In comparison, the RBD for the Lion Air 610 crash identified gaps in the design of the MCAS and internal communication among airline entities.
As the case study of the Lion Air 610 crash mainly addresses systematic failures, the FTA proved to be easily applicable. However, the FTA of the Virginia Tech Shooting showed limitations due to the complexity of the case. The authors are aware that Cho’s personality might be seen more as a symptom rather than a cause. However, in this case, it was interpreted as a cause since this particular incident would not have happened without Cho and the root causes were related to issues in communication and missing supporting features.
There are two main perceived criticisms of our proposed approach. The first relates to the limited value added, whereas the latter is concerned with assumption of simplicity of cause and effect. Thus, the first point is about the true added value of using FTA and RBD, which is claimed to be limited, as these tools did not discover new lessons. In response to this criticism, one can say that FTA helps to organise relationships between factors and such mental model in the form of a diagram might be easy to recall and hence saves much time in going through the large number of pages that is typical of any incident investigation report. Regarding the second point, of being constrained by a strict cause and effect relationship that may not capture complexity of the incident, one can argue that such limitation is in a way a blessing, as, by following such logical way of thinking that is strictly relying on just a couple of logic gates, this approach provides a rational way of thinking to reach logical conclusions. It is not the intention of this paper to offer new insight into these tragic cases but instead to present approaches that will help to develop and support organisational learning, highlighting the diversity of cases for application of the approach and, crucially, offering a simplified method to capture key information rather than extended narrative, which can dilute learning for organisations.
In conclusion, the results of integrating the information obtained through the methods of FTA and RBD can support the various stakeholders of the events to appropriately allocate their resources, improve processes in terms of standard operating procedures and routines and thereby mitigate future disasters. Thus, organisational learning is stimulated and organisational resilience can be improved. Again, we stress here that learning implies change of behaviour to avert similar incidents from occurring and accordingly unlearning implies abandoning such practices. However, the learning process varied between both cases due to having investigations closed and failures detected in the case of the Virginia Tech Shooting and ongoing investigations in the case of the Lion Air 610 crash.
Thus, can the analysis be the motivation for organisational learning? If we define organisational “learning” from failures as consisting of three main streams: (1) feedback from users to design; (2) use of advanced modelling and analysis tools; and (3) incorporation of multidisciplinary and generic lessons, as proposed by Labib[10], then, using this lens, the answer is yes. Both cases showed that there is potential to learn from the disasters as: (1) users’ feedback to design through specific lessons and actions identified; (2) the integration of failure analysis tools such as FTA and RBD; and (3) the generic lessons learned have been applied in both safety and security domains.
Declarations
AcknowledgmentsWe would like to acknowledge the feedback comments received by the reviewers.
Authors’ contributionsConceptualisation, data analysis, formal analysis and writing: Shmidt B
Advise on investigation, methodology and supervision: Labib A
Validation, visualisation, review and editing: Hadleigh-Dunn S
Availability of data and materialsNot applicable.
Financial support and sponsorshipNone.
Conflicts of interestAll authors declared that there are no conflicts of interest.
Ethical approval and consent to participateNot applicable.
Consent for publicationNot applicable.
Copyright© The Author(s) 2020.
REFERENCES
1. Labib A, Read M. Not just rearranging the deckchairs on the Titanic: Learning from failures through Risk and Reliability Analysis. Safety Sci 2013;51:397-413.
2. Sitkin S. Learning through failure: the strategy of small losses. Res Organizational Behave 1992;14:231-66.
3. Cannon MD, Edmondson AC. Failing to learn and learning to fail (Intelligently): how great organizations put failure to work to innovate and improve. Long Range Planning 2005;38:299-319.
5. Madsen PM, Desai V. Failing to learn? The effects of failure and success on organizational learning in the global orbital launch vehicle industry. Academy Management J 2010;53:451-76.
6. Smith D, Elliott D. Exploring the barriers to learning from crisis: organizational learning and crisis. Management Learning 2007;38:519-38.
7. Taleb N. The Black Swan. London, England: Penguin Books Ltd; 2007.
8. Fortune J, Peters G. Learning from failure: the systems approach. Chichester: John Wiley & Sons Ltd; 1995.
9. Knight R, Pretty D. The impact of catastrophes on shareholder value. The Oxford Executive Research Briefings. Templeton College: University of Oxford; 1997.
10. Labib A. Learning from failures: decision analysis of major disasters. Elsevier Butterworth-Hein; 2014.
11. Argyris C. On organizational learning. 2nd ed. Oxford: Blackwell Publishing; 1999.
13. Toft B, Renolds S. Learning from disasters: a management approach. 3rd ed. Basingstoke: Palgrave Macmillan; 2005.
14. Weinzimmer LG, Esken CA. Learning from mistakes: how mistake tolerance positively affects organizational learning and performance. J Appl Behav Sci 2017;53:322-48.
15. Starbuck WH. Unlearning ineffective or obsolete technologies. Int J Technol Management 1996;11:725-37.
17. Kunert S. Strategies in failure management: scientific insights, case studies and tools. Cham: Springer International Publishing; 2018.
18. Pranesh V, Palanichamy K, Saidat O, Peter N. Lack of dynamic leadership skills and human failure contribution analysis to manage risk in Deep Water Horizon oil platform. Safety Sci 2016;92:85-93.
19. Balmer JMT, Powell SM, Greyser SA. Explicating ethical corporate marketing. Insights from the BP deepwater horizon catastrophe: the ethical brand that exploded and then imploded. J Business Ethics 2011;102.
20. Saadat V, Saadat Z. Organizational learning and as a key role of organizational success. Procedia Social Behav Sci 2016;230:219-25.
21. Labib A. Learning (and unlearning) from failures: 30 years on from Bhopal to Fukushima an analysis through reliability engineering techniques. Process Safety Environmental Protection 2015;97:80-90.
22. Mahler JG. Organizational learning at NASA: the Challenger and Columbia accidents. Georgetown University Press; 2009.
23. Kletz TA. Lessons from disaster: how organizations have no memory and accidents recur. IChemE; 1993.
24. Reason J. Managing the risk of organizational accidents. Aldershot, Hants, Ashgate; 1997.
25. Reason J, Hollnagel E, Paries J. Revisiting the Swiss cheese model of accidents. J Clini Engineering 2006;27:110-5.
26. Perrow C. Normal accidents: living with high-risk technologies. New York: Basic Books; 1984.
27. Rochlin GI, La Porte TR, Roberts KH. The self-designing high reliability organization. 1987. Reprinted in Naval War College Review 1998;51:17.
28. Saleh JH, Marias KB, Bakolas E, Cowlagi RV. Highlights from the literature on accident causation and system safety: review of major ideas, recent contributions, and challenges. Reliability Engineering System Safety 2010;95:1105-16.
29. Rijpma JA. Complexity, tight-coupling and reliability: connecting normal accidents theory and high reliability theory. J Contingencies Crisis Management 1997;5:15-23.
30. Vieweg S, Palen L, Liu SB, Hughes AL, Sutton JN. Collective intelligence in disaster: Examination of the phenomenon in the aftermath of the 2007 Virginia Tech shooting. Boulder, CO: University of Colorado; 2008.
31. Palen L, Vieweg S, Liu SB, Hughes AL. Crisis in a networked world: Features of computer-mediated communication in the April 16, 2007, Virginia Tech event. Social Sci Computer Rev 2009;27:467-80.
32. Hong JS, Cho H, Lee AS. Revisiting the Virginia Tech shootings: an ecological systems analysis. J of Loss and Trauma 2010;15:561-75.
33. Virginia Tech Review Panel. Mass shootings at Virginia Tech. Addendum to the report of the review panel; 2009. Available from: https://scholar.lib.vt.edu/prevail/docs/April16ReportRev20091204.pdf [Last accessed on 24 Apr 2020].
34. Labib A, Hadleigh-Dunn S, Mahfouz A, Gentile M. Operationalising learning from rare events: framework for middle humanitarian operations managers. Production Operations Management 2019;28.
35. Caruso K. Virginia Tech Massacre. Available from: http://www.virginiatechmassacre.com/index.html [Last accessed on 24 Apr 2020].
36. CNN (2018). Virginia Tech Shooting Fast Facts. Available from: https://edition.cnn.com/2013/10/31/us/virginia-tech-shootings-fast-facts/index.html [Last accessed on 24 Apr 2020].
37. BBC. Lion Air JT610 crash: What the preliminary report tells us. Available from: https://www.bbc.co.uk/news/world-asia-46373125 [Last accessed on 24 Apr 2020].
38. Komite Nasional Keselamatan Transportasi. Preliminary Aircraft Accident Report. Available from: https://reports.aviation-safety.net/2018/20181029-0_B38M_PK-LQP_PRELIMINARY.pdf [Last accessed on 24 Apr 2020].
39. Gröndahl M, McCann A, Glanz J, Migliozzi B, Syam U. In 12 minutes, everything went wrong. How the pilots of Lion Air Flight 610 lost control. Available from: https://www.nytimes.com/interactive/2018/12/26/world/asia/lion-air-crash-12-minutes.html [Last accessed on 24 Apr 2020].
40. Learmount D. Lion Air lessons. Available from: https://www.aerosociety.com/news/lion-air-lessons/ [Last accessed on 24 Apr 2020].
Cite This Article
Export citation file: BibTeX | RIS
OAE Style
Schmidt B, Labib A, Hadleigh-Dunn S. Learning and unlearning from disasters: an analysis of the Virginia Tech, USA shooting and the Lion Air 610 Airline crash. J Surveill Secur Saf 2020;1:1-15. http://dx.doi.org/10.20517/jsss.2019.02
AMA Style
Schmidt B, Labib A, Hadleigh-Dunn S. Learning and unlearning from disasters: an analysis of the Virginia Tech, USA shooting and the Lion Air 610 Airline crash. Journal of Surveillance, Security and Safety. 2020; 1(1): 1-15. http://dx.doi.org/10.20517/jsss.2019.02
Chicago/Turabian Style
Schmidt, Bianca, Ashraf Labib, Sara Hadleigh-Dunn. 2020. "Learning and unlearning from disasters: an analysis of the Virginia Tech, USA shooting and the Lion Air 610 Airline crash" Journal of Surveillance, Security and Safety. 1, no.1: 1-15. http://dx.doi.org/10.20517/jsss.2019.02
ACS Style
Schmidt, B.; Labib A.; Hadleigh-Dunn S. Learning and unlearning from disasters: an analysis of the Virginia Tech, USA shooting and the Lion Air 610 Airline crash. J. Surveill. Secur. Saf. 2020, 1, 1-15. http://dx.doi.org/10.20517/jsss.2019.02
About This Article
Copyright

Data & Comments
Data



 Cite This Article 28 clicks
Cite This Article 28 clicks

 Like This Article 9
likes
Like This Article 9
likes







Comments
Comments must be written in English. Spam, offensive content, impersonation, and private information will not be permitted. If any comment is reported and identified as inappropriate content by OAE staff, the comment will be removed without notice. If you have any queries or need any help, please contact us at support@oaepublish.com.